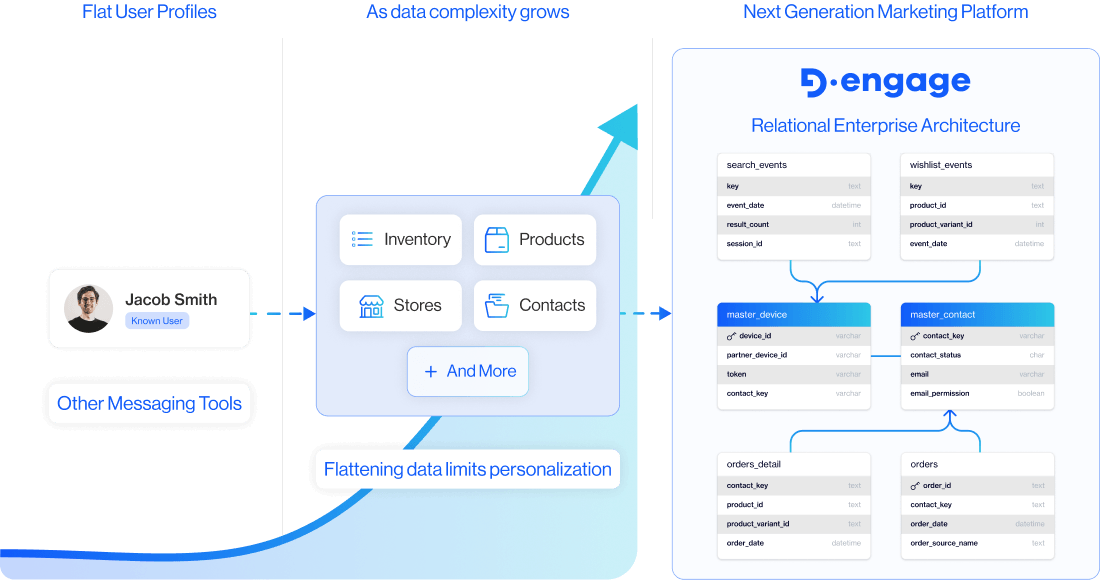
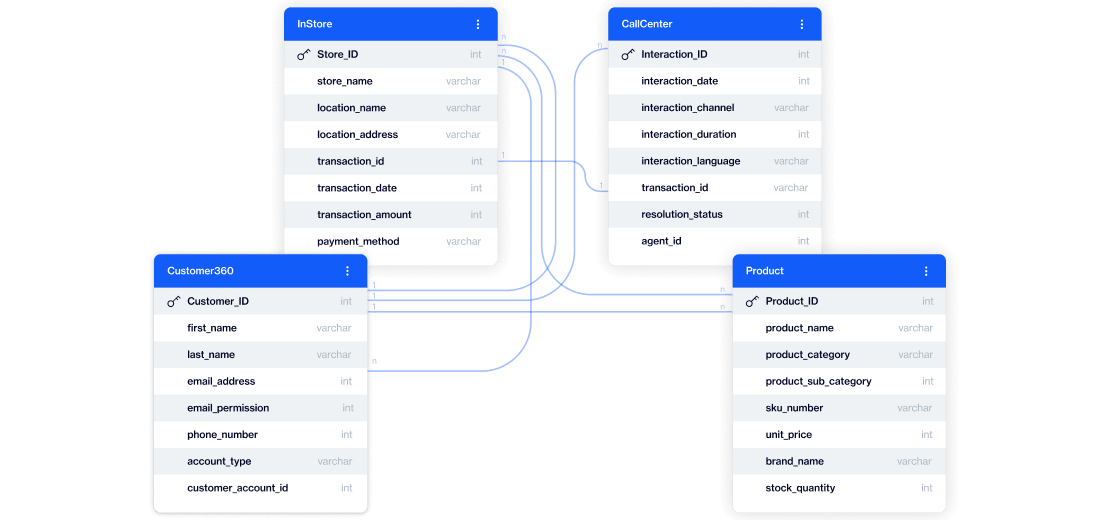
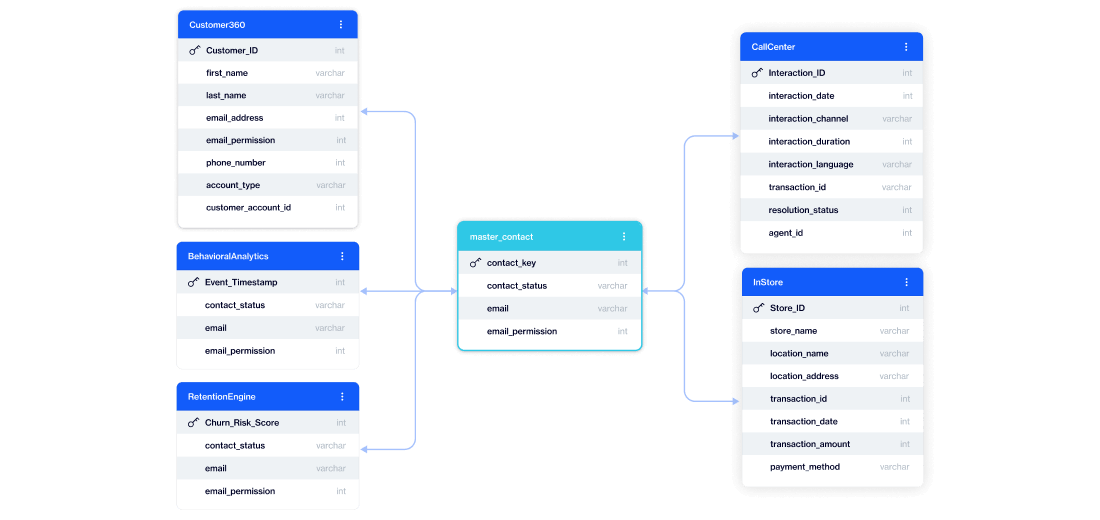
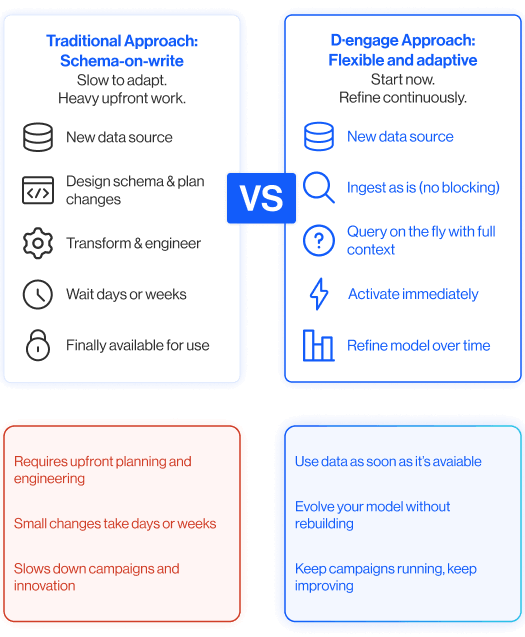
In traditional setups, combining relational depth with analytical speed requires complex SQL. Queries involve multiple joins, subqueries, and constant adjustments as the data model evolves.
For marketing teams, this translates into slow audience builds, brittle logic, and a dependency on data engineering for anything beyond basic segmentation. And for a marketing leader, this creates a bottleneck because campaigns depend on technical teams to move forward.
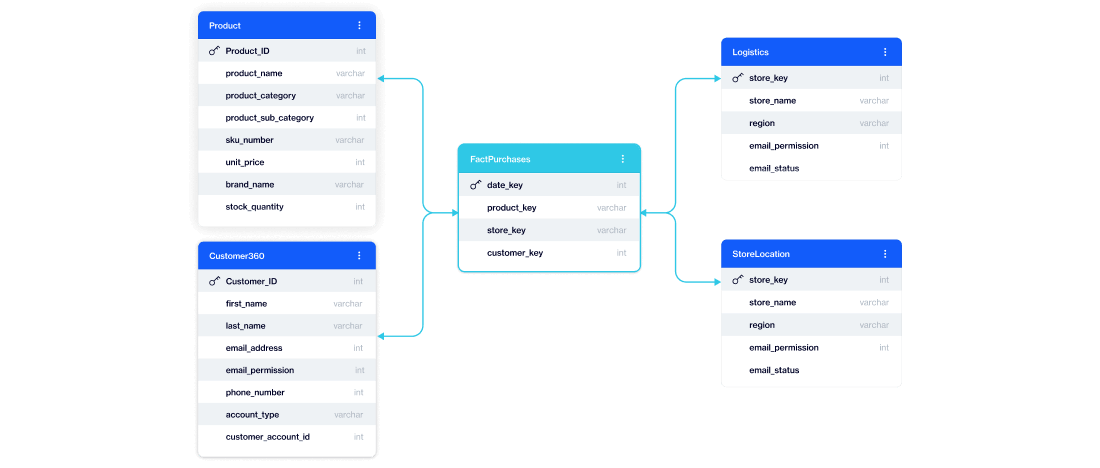
D·engage removes that complexity by handling the underlying data relationships for you.
Instead of manually defining how tables connect, the platform understands those relationships natively. When you build an audience, you’re not writing joins or stitching tables together. You’re simply defining the conditions you care about across customers, products, transactions, or any other data in your model.
Behind the scenes, D·engage translates those conditions into the required joins and query logic automatically.
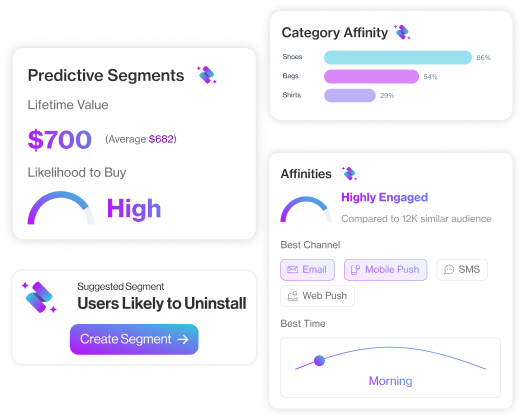
That means marketers can work with complex, multi-table data in the same way they would build a simple segment without relying on engineering support every time the logic changes.
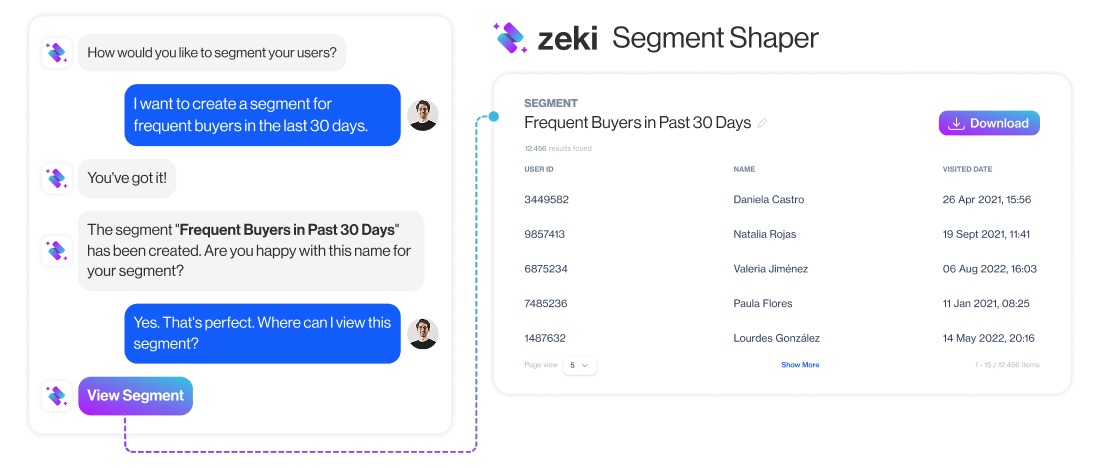
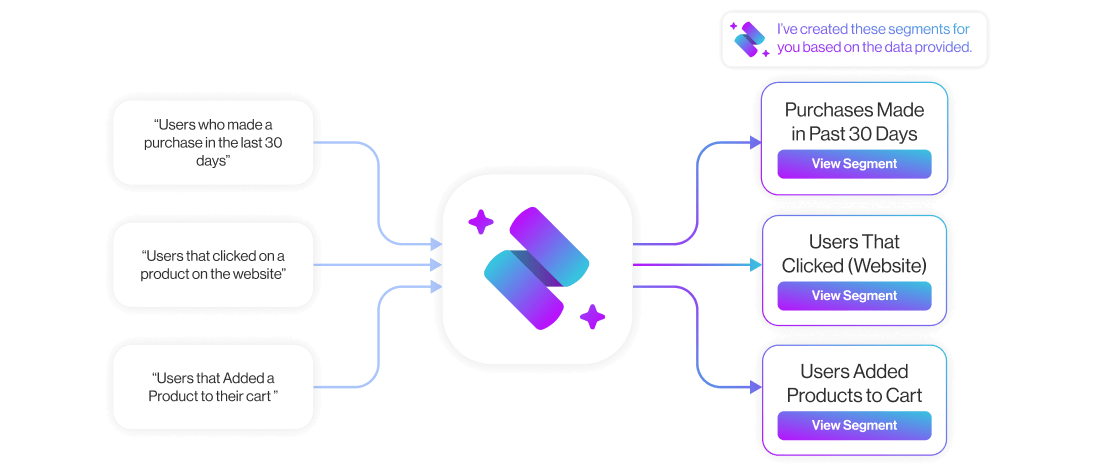
In D·engage, this is what eliminating join complexity looks like in practice:
- A marketer types: “users who added to cart but didn’t buy in the last 3 days.”
- Segment Shaper, part of Zeki AI, builds the audience instantly.
No SQL, manual joins, or waiting on a data team.
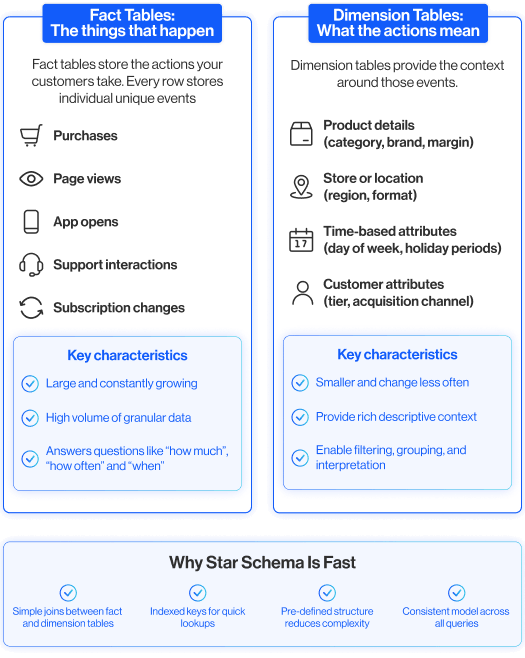
The relational model and star schema are working behind the scenes. The marketer simply describes what they need, and the platform translates that into the required logic automatically.
This is the difference between data architecture in theory and marketing reality.